[문제] 수강신청 준비하기
2,000명의 품생사 대학교 학생들이 수강신청을 했습니다.
수강신청에는 다음 3개의 조건이 있습니다.
- “information technology” 과목은 심화과목이라 1학년은 수강할 수 없습니다.
- “commerce” 과목은 기초과목이고 많은 학생들이 듣는 수업이라 4학년은 수강할 수 없습니다.
- 수강생이 5명이 되지 않으면 강의는 폐강되어 수강할 수 없습니다.
기존 DataFrame에 “status”라는 이름의 column을 추가하고, 학생이 수강 가능한 상태이면 “allowed”, 수강 불가능한 상태이면 “not allowed”를 넣어주세요.

조건 1: “information technology” 과목은 심화과목이라 1학년은 수강할 수 없습니다.
총 세 개의 조건이 있습니다.
- “information technology” 과목은 심화과목이라 1학년은 수강할 수 없습니다.
- “commerce” 과목은 기초과목이고 많은 학생들이 듣는 수업이라 4학년은 수강할 수 없습니다.
- 수강생이 5명이 되지 않으면 강의는 폐강되어 수강할 수 없습니다
이 조건이 “status”라는 column에 “allowed” 또는 “not allowed” 형태로 저장되어야 합니다.
먼저 "status"라는 column을 만들고, 모든 데이터를 "allowed"로 채워봅시다.
import pandas as pd
df = pd.read_csv('data/enrolment_1.csv')
df["status"] = "allowed"이제 여기에서 각 조건에 해당하는 경우, "not allowed"로 변경해 주면 됩니다.
“information technology” 과목을 수강하는 모든 데이터를 boolean1에 저장하고, 1학년에 해당하는 모든 데이터를 boolean2에 저장합시다.
boolean1 = df["course name"] == "information technology"
boolean2 = df["year"] == 1
그리고 이 두 값에 & 불린 연산을 하면, 두 조건을 동시에 만족하는 데이터만 인덱싱할 수 있습니다.
boolean1 = df["course name"] == "information technology"
boolean2 = df["year"] == 1
조건 2: “commerce” 과목은 기초과목이고 많은 학생들이 듣는 수업이라 4학년은 수강할 수 없습니다.
“commerce” 과목을 수강하는 모든 데이터를 boolean3에 저장하고, 4학년에 해당하는 모든 데이터를 boolean4에 저장합니다.
boolean3 = df["course name"] == "commerce"
boolean4 = df["year"] == 4
그리고 이 두 값에 & 불린 연산을 하면, 두 조건을 동시에 만족하는 데이터만 인덱싱할 수 있습니다.
df.loc[boolean3 & boolean4, "status"] = "not allowed"
조건 3: 수강생이 5명이 되지 않으면 강의는 폐강되어 수강할 수 없습니다.
우선 status가 allowed인 데이터만 모아 봅니다.
allowed = df["status"] == "allowed"
value_counts()를 사용하면, 각 과목별 신청 인원을 확인할 수 있습니다.
course_counts = df.loc[allowed, "course name"].value_counts()
course_counts
arts 158
science 124
commerce 101
english 56
education 41
...
chemstry 1
jmc 1
b.ed 1
pgdca 1
sciences 1
Name: course name, Length: 296, dtype: int64
각 과목별 신청 인원이 5 이하인 과목의 index만 골라서 리스트로 만들어줍니다.
closed_courses = list(course_counts[course_counts < 5].index)
print(closed_courses)
['refactoring', 'computer architecture', 'engg. & tech.', ... , 'computer science (lateral entry)', 'arts/science', 'pg.diploma', 'aqua culture']
이제 폐강 과목에 대한 리스트가 확보되었습니다. for문을 통해 not allowed 문구를 넣어줍니다.
for course in closed_courses:
df.loc[df["course name"] == course, "status"] = "not allowed"
이제 이 세 코드를 모두 합치면 우리가 원하는 결과를 얻을 수 있습니다.
import pandas as pd
df = pd.read_csv('data/enrolment_1.csv')
df["status"] = "allowed"
# 조건 1
boolean1 = df["course name"] == "information technology"
boolean2 = df["year"] == 1
df.loc[boolean1 & boolean2, "status"] = "not allowed"
# 조건 2
boolean3= df["course name"] == "commerce"
boolean4= df["year"] == 4
df.loc[boolean3& boolean4, "status"] = "not allowed"
# 조건 3
allowed = df["status"] == "allowed"
course_counts = df.loc[allowed, "course name"].value_counts()
closed_courses = list(course_counts[course_counts < 5].index)
for course in closed_courses:
df.loc[df["course name"] == course, "status"] = "not allowed"
df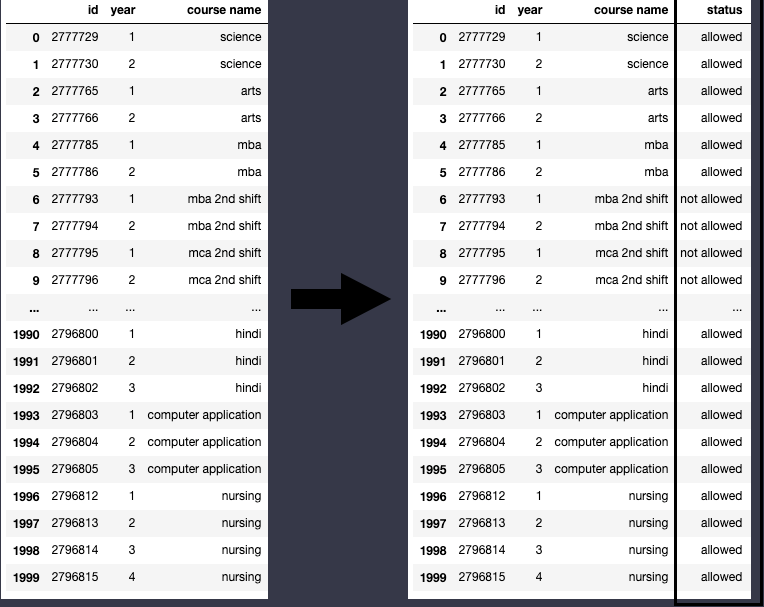

요약 : sparta coding club, 스파르타 코딩, 코드잇, 노마드 코더, 프로그래밍, 직장인 코딩, 내일 배움 카드 코딩, 밀크티 코딩, 초등 코딩, 아이스크림 코딩, 코딩 소프트웨어, 구글 데이터 스튜디오, 데이터 웨어 하우스 , 빅 데이터 클라우드
'TESTING > PROGREMING' 카테고리의 다른 글
| [데이터 사이언스 코딩 - Chap.13] 실습 실리콘밸리에 일하는 사람 찾기 문제 풀어보기 (0) | 2021.08.19 |
|---|---|
| [데이터 사이언스 코딩 - Chap.12] 실습 강의실 배정하기 문제 풀어보기 (0) | 2021.08.09 |
| [데이터 사이언스 코딩 - Chap.10] 실습 DataFrame 퍼즐 문제 풀어보기 (0) | 2021.08.03 |
| [데이터 사이언스 코딩 - Chap.9] 실습 서류 전형 합격 여부 문제 풀어보기 (0) | 2021.08.02 |
| [데이터 사이언스 코딩 - Chap.8] 실습 - 잘못된 DataFrame 고치기 문제 풀어보기 (0) | 2021.08.01 |