[문제] 실리콘 밸리에 일하는 사람 찾기 1탄
실리콘 밸리에서 일하는 사람들의 정보가 있습니다.
직업 종류, 인종, 성별 등이 포함되어 있습니다.
실리콘 밸리에서 일하는 남자 관리자 (Managers)에 대한 인종 분포를 막대그래프로 다음과 같이 그려봅시다.
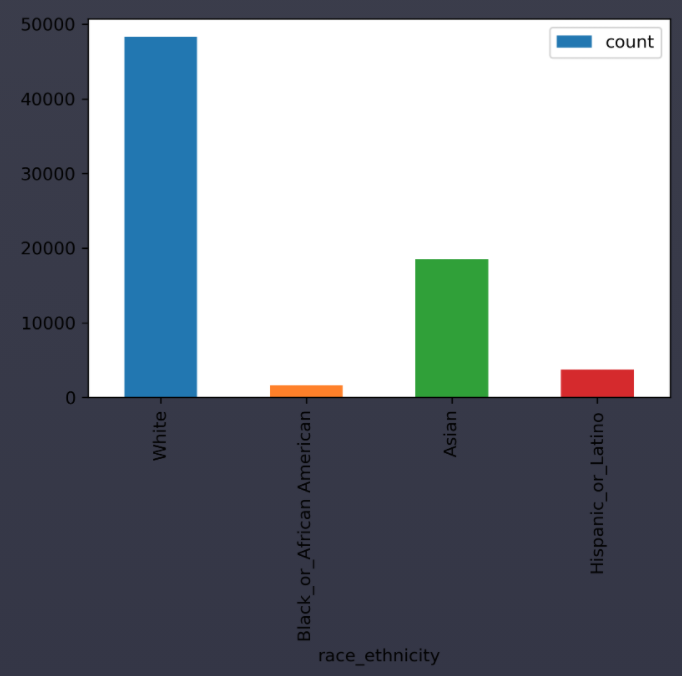
과제 해설
우선 데이터 내용을 확인해 봅시다.
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/silicon_valley_summary.csv')
df
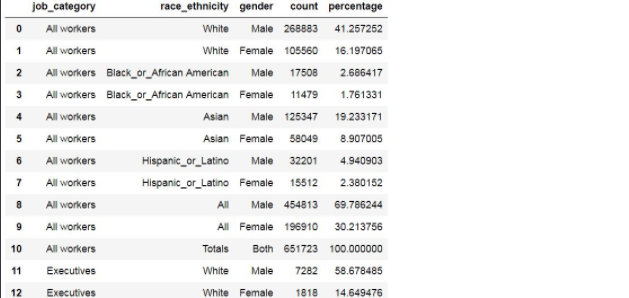
우리는 관리자 (Manager) 직군의 남자에 대한 그래프를 그리려고 합니다.
따라서 'job_category'는 'Manager'이고, 'gender'는 'Male'인 데이터만 뽑아봅시다.
boolean_male = df['gender']=='Male'
boolean_manager = df['job_category'] == 'Managers'
df[boolean_male & boolean_manager]
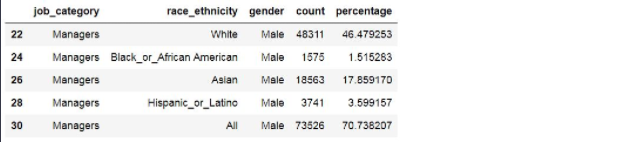
각 인종에 대한 데이터만 그래프로 그리고 싶으니, 'race_ethnicity'가 'All'인 경우는 제외해야겠죠?
boolean_male = df['gender']=='Male'
boolean_manager = df['job_category'] == 'Managers'
boolean_not_all = df['race_ethnicity'] != 'All'
df[boolean_male & boolean_manager & boolean_not_all]

이제 이 데이터를 plot 메소드를 이용해서 그래프로 그려주면 됩니다.
df[boolean_male & boolean_manager & boolean_not_all].plot(kind='bar', x='race_ethnicity', y='count')
전체 정답 코드는 다음과 같습니다.
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/silicon_valley_summary.csv')
boolean_male = df['gender']=='Male'
boolean_manager = df['job_category'] == 'Managers'
boolean_not_all = df['race_ethnicity'] != 'All'
df[boolean_male & boolean_manager & boolean_not_all].plot(kind='bar', x='race_ethnicity', y='count')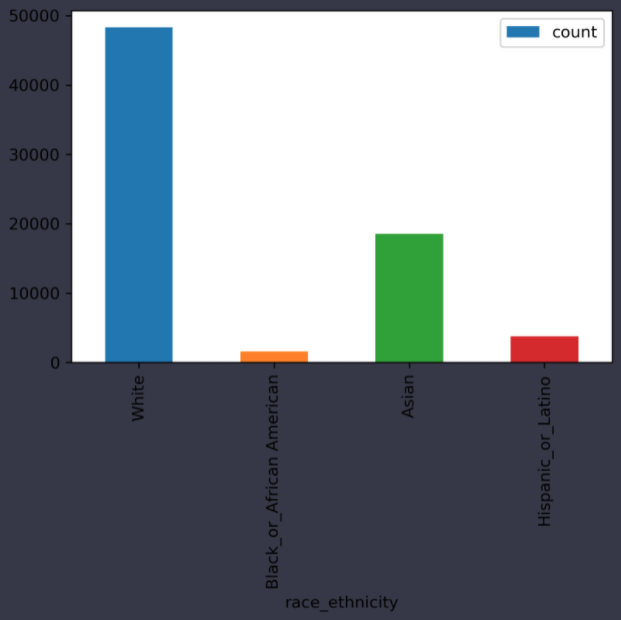
실리콘 밸리에 일하는 사람 찾기 2탄
이번에는 어도비 (Adobe)의 직원 분포를 한번 살펴봅시다.
어도비 전체 직원들의 직군 분포를 파이 그래프로 그려보세요.
(인원이 0인 직군은 그래프에 표시되지 않아야 합니다.)
과제 해설
먼저 주어진 데이터를 살펴봅시다.
%matplotlib inline
import pandas as pd
df = pd.read_csv("data/silicon_valley_details.csv")
df
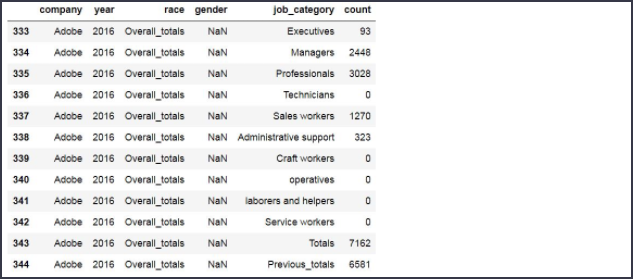
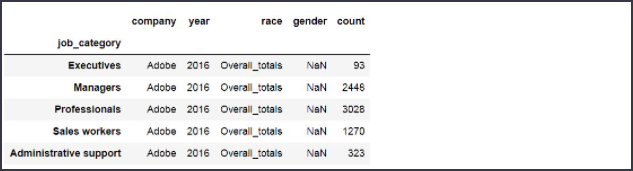
이제 여기에서 회사 'company'는 'Adobe', 인종 'race'는 'Overall_totals'인 데이터만 골라내 봅시다
boolean_adobe = df['company'] == 'Adobe'
boolean_all_races = df['race'] == 'Overall_totals'
df[boolean_adobe & boolean_all_races]
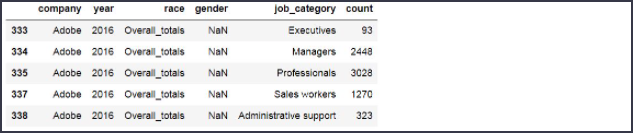
좀 더 깔끔하게 정리하기 위해서, 'count'가 0인 데이터는 제거하고, 'job_category'가 'Totals' 혹은 'Previous_totals'인 데이터도 제거합시다.
boolean_adobe = df['company'] == 'Adobe'
boolean_all_races = df['race'] == 'Overall_totals'
boolean_count = df['count'] != 0
boolean_job_category = (df['job_category'] != 'Totals') & (df['job_category'] != 'Previous_totals')
df_adobe = df[boolean_adobe & boolean_all_races & boolean_count & boolean_job_category]
df_adobe
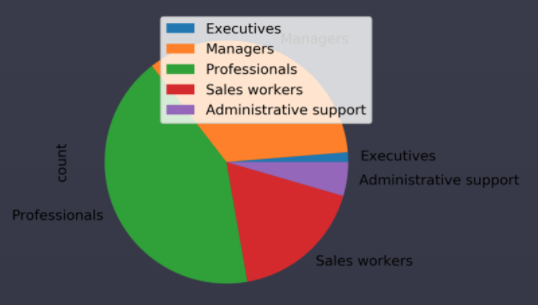
이제 그래프를 그려봅시다.
df_adobe.plot(kind='pie', y= 'count')
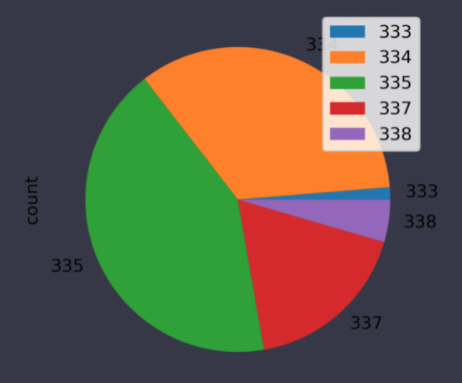
그런데 그래프가 조금 이상합니다.
파이 그래프는 index를 기준으로 이름표를 붙여주게 됩니다.
우리가 원하는 이름표는 직업 카테고리이니까, set_index를 활용해서 index를 바꿔줍시다.
df_adobe.set_index('job_category', inplace=True)
이제 plot 메소드로 그래프를 그려주면 됩니다.
df_adobe.plot(kind='pie', y= 'count')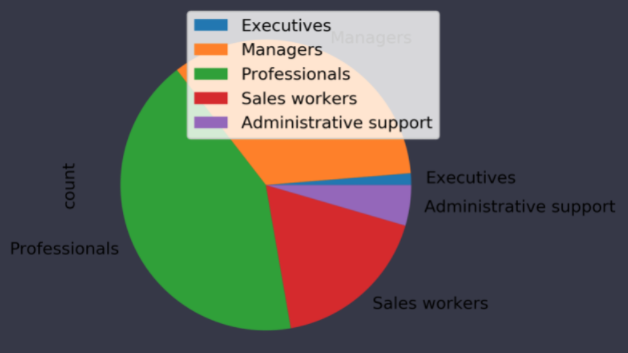
전체 정답 코드는 다음과 같습니다.
%matplotlib inline
import pandas as pd
df = pd.read_csv("data/silicon_valley_details.csv")
boolean_adobe = df['company'] == 'Adobe'
boolean_all_races = df['race'] == 'Overall_totals'
boolean_count = df['count'] != 0
boolean_job_category = (df['job_category'] != 'Totals') & (df['job_category'] != 'Previous_totals')
df_adobe = df[boolean_adobe & boolean_all_races & boolean_count & boolean_job_category]
df_adobe.set_index('job_category', inplace=True)
df_adobe.plot(kind='pie', y= 'count')
요약 : sparta coding club, 스파르타 코딩, 코드잇, 노마드 코더, 프로그래밍, 직장인 코딩, 내일 배움 카드 코딩, 밀크티 코딩, 초등 코딩, 아이스크림 코딩, 코딩 소프트웨어, 구글 데이터 스튜디오, 데이터 웨어 하우스 , 빅 데이터 클라우드
'TESTING > PROGREMING' 카테고리의 다른 글
| [데이터 사이언스 코딩 - Chap.14] 실습 음료의 칼로리 문제 풀어보기 (0) | 2021.08.26 |
|---|---|
| [데이터 사이언스 코딩 - Chap.12] 실습 강의실 배정하기 문제 풀어보기 (0) | 2021.08.09 |
| [데이터 사이언스 코딩 - Chap.11] 실습 수강신청 준비하기 문제 풀어보기 (0) | 2021.08.08 |
| [데이터 사이언스 코딩 - Chap.10] 실습 DataFrame 퍼즐 문제 풀어보기 (0) | 2021.08.03 |
| [데이터 사이언스 코딩 - Chap.9] 실습 서류 전형 합격 여부 문제 풀어보기 (0) | 2021.08.02 |