반응형
과제 - DataFrame 인덱싱
데이터의 중요성을 깨달은 “품생카드”와 “품사카드”가 협업을 하기로 결정했습니다.
두 카드사는 사람들이 요일별로 지출하는 평균 금액을 “요일”, “식비", “교통비”, “문화생활비”, “기타” 카테고리로 정리해서 우리에게 공유해 주기로 했는데요. 각각 lq.csv 파일과 dq.csv 파일을 보냈습니다.
두 회사의 데이터를 활용해서, 사람들의 요일별 문화생활비를 분석해보려 합니다. 아래와 같은 형태로 출력이 되도록 DataFrame을 만들어보세요.
day lq dq
0 MON 4308 5339
1 TUE 7644 3524
2 WED 5674 5364
3 THU 8621 9942
4 FRI 23052 33511
5 SAT 15330 19397
6 SUN 19030 19925
데이터 파악하기
먼저 각각의 DataFrame을 읽어들입니다.
import pandas as pd
samsong_df = pd.read_csv('data/lq.csv')
samsong_df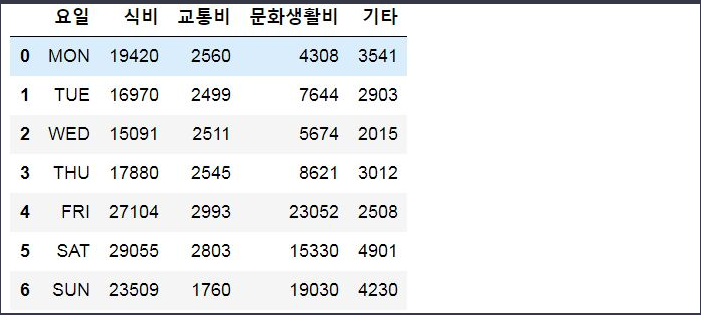
import pandas as pd
hyundee_df = pd.read_csv('data/dq.csv')
hyundee_df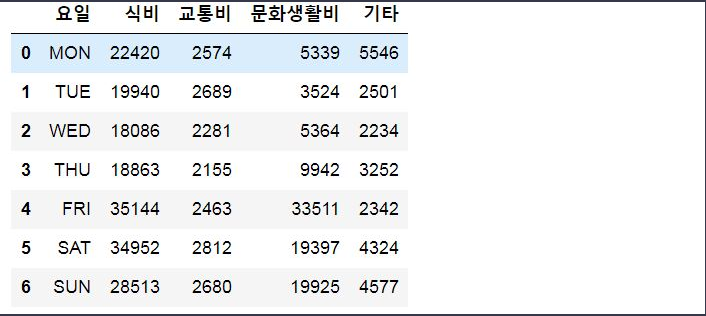
이 중에서 우리가 활용하고 싶은 데이터는 '요일', 그리고 lq_df의 '문화생활비', dq_df의 '문화생활비' 입니다. 각각을 이렇게 가져올 수 있습니다.
파이썬 사전(dictionary) 만들기
DataFrame을 만드는 여러 방법 중에 파이썬 사전(dictionary)을 활용해 봅시다.
우리가 원하는 세 개의 column은 'day', 'lq', 'dq' 입니다.
그럼 사전을 이렇게 만들 수 있습니다.
{'day': lq_df['요일'],
'lq': lq_df['문화생활비'],
'dq': dqe_df['문화생활비']}
DataFrame 만들기
이제 값을 활용해서 DataFrame을 만들면 됩니다.
import pandas as pd
lq_df = pd.read_csv('data/lq.csv')
dq_df = pd.read_csv('data/dq.csv')
combined_df = pd.DataFrame({
'day': lq_df['요일'],
'lq': lq_df['문화생활비'],
'dq': dq_df['문화생활비']
})
combined_df
day lq dq
0 MON 4308 5339
1 TUE 7644 3524
2 WED 5674 5364
3 THU 8621 9942
4 FRI 23052 33511
5 SAT 15330 19397
6 SUN 19030 19925
DataFrame 인덱싱 문법 정리
| 이름으로 인덱싱하기 | 기본 형태 | 단축 형태 |
| 하나의 row 이름 | df.loc["row4"] | |
| row 이름의 리스트 | df.loc[["row4", "row5", "row3"]] | |
| row 이름의 리스트 슬라이싱 | df.loc["row2":"row5"] | df["row2":"row5"] |
| 하나의 column 이름 | df.loc[:, "col1"] | df["col1"] |
| column 이름의 리스트 | df.loc[:, ["col4", "col6", "col3"]] | df[["col4", "col6", "col3"]] |
| column 이름의 리스트 슬라이싱 | df.loc[:, "col2":"col5"] |
| 위치로 인덱싱하기 | 기본 형태 | 단축 형태 |
| 하나의 row 이름 | df.iloc[8] | |
| row 이름의 리스트 | df.iloc[[4, 5, 3]] | |
| row 이름의 리스트 슬라이싱 | df.iloc[2:5] | df[2:5] |
| 하나의 column 이름 | df.iloc[:, 3] | |
| column 이름의 리스트 | df.iloc[:, [3, 5, 6]] | |
| column 이름의 리스트 슬라이싱 | df.iloc[:, 3:7] |

요약 : sparta coding club, 스파르타 코딩, 코드잇, 노마드 코더, 프로그래밍, 직장인 코딩, 내일 배움 카드 코딩, 밀크티 코딩, 초등 코딩, 아이스크림 코딩, 코딩 소프트웨어, 자바 스크립트 국비 지원, 자바 스크립트 교육
반응형
'TESTING > PROGREMING' 카테고리의 다른 글
| [데이터 사이언스 코딩 - Chap.8] 실습 - 잘못된 DataFrame 고치기 문제 풀어보기 (0) | 2021.08.01 |
|---|---|
| [데이터 사이언스 코딩 - Chap.7] 실습 DataFrame 인덱싱 문제 풀어보기(2) (0) | 2021.07.29 |
| [데이터 사이언스 코딩 - 정보] Pandas : DataFrame을 만드는 방법 알아보기 (0) | 2021.07.24 |
| [데이터 사이언스 코딩 - Chap.5] 실습 Pandas 문제 풀어보기 (0) | 2021.07.23 |
| [데이터 사이언스 코딩 - Chap.4] 실습 numpy 기본 통계 문제 풀어보기 (0) | 2021.07.21 |